
聚合查询
MongoDB 中通过 aggregate([{...}]) 方法来完成聚合查询。
比较常见的聚合查询表达式有:$sum、$max、$push、$first、$last 等。
表达式只是执行具体的操作,聚合查询的核心是管道的概念,有点类似 Linux 系统的管道,用于将当前输出的结果作为下一个命令的参数。
$lookup 便是聚合框架中常见一种操作。
此外还有,$project、$match、$unwind、$group、$sort等,本文中会提供一个完整的查询实例,其中会使用到这些内容。
$lookup
$lookup 是 MongoDB 3.2 版本出现的新功能。
其主要作用是对同一数据库中未分片集合执行左外部联接,从“联接”的集合中过滤文档进行处理。
对每个输入的文档,$lookup 阶段会添加一个新的数组字段,其中元素是“联接”集合中匹配出来的文档。
基础语法
注意:在 MongoDB 3.6 版本中,$lookup 得以被增强,这里先列取基本语法,本文案例也是依照基本语法编写。
{
$lookip:
{
from: "连接的附表",
localField: "主表外联的字段",
foreignField: "附表关联的字段",
as: "加入字段"
}
}
增强语法
MongoDB 3.6 版本的增强语法。
{
$lookip:
{
from: "主表",
let: {var1: exp1,var2:exp2}, // 可选参数,指定管道字段的变量,作为入参放到接下来的管道中,可以实现多条件级联
pipeline: [{...}], // 管道,要连接的集合管道,全部返回指定为空管道[]
as: "加入字段"
}
}
基本语法实例
如果您使用过传统的 SQL 数据库,将其理解为 left join 就会很快明白其中的意思。
现有 USER 和 USER_EX 两个集合,现在希望通过 USER 集合的 name 字段关联查询出 USER_EX 中的数据。
// USER
{
"_id" : ObjectId("60ebf6e17b2db72987c04828"),
"name" : "mebugs",
"where" : "wuxi"
}
// USER_EX
{
"_id" : ObjectId("60ebf7067b2db72987c0482d"),
"name" : "mebugs",
"size" : "17"
}
查询语句:
db.getCollection("USER").aggregate([
{
$lookup: {
from: "USER_EX",
localField: "name",
foreignField: "name",
as: "ex"
}
}
])
查询结果:
// 关联的数据将已数组的形式存在于指定的 as 字段
{
"_id" : ObjectId("60ebf6e17b2db72987c04828"),
"name" : "mebugs",
"where" : "wuxi",
"ex" : [
{
"_id" : ObjectId("60ebf7067b2db72987c0482d"),
"name" : "mebugs",
"size" : "17"
}
]
}
增强示例
$unwind 组合
$unwind 组合,可以将数组的内容拆分成记录。
有的时候需要统计总量,如果关联的内容仅仅存在在数组中会使得程序处理变得麻烦,因此通过 $unwind 组合可以实现对关联的数组解开。
db.getCollection("USER").aggregate([
{
$lookup: {
from: "USER_EX",
localField: "name",
foreignField: "name",
as: "ex"
}
},
{
$unwind: {
path: "$ex",
preserveNullAndEmptyArrays: true // 空数组记录保留
}
}
])

$project格式化输出
数组变成对象之后,程序相对好处理多了,但是还不行,我不希望为 ex 单独定义一个子对象,而是希望直接取出 ex 中的字段。
这时候可以通过 $project 对输入的文档进行文档结构修改,可以自由定义字段映射/增加/修改/组合/拼接/格式化等操作。
关于 $project 的更多用法,后面单独去详细描述。
db.getCollection("USER").aggregate([
{
$lookup: {
from: "USER_EX",
localField: "name",
foreignField: "name",
as: "ex"
}
},
{
$unwind: {
path: "$ex",
preserveNullAndEmptyArrays: true // 空数组记录保留
}
},
{
$project: {
_id: 0, // 或略输出这个字段
name: "$name", // 直接映射
city: "$where", // 修改字段名
size: "$ex.size", // 映射子字段
unit: { $concat: ["$ex.size", "cm"] } // 拼接输出
}
}
])
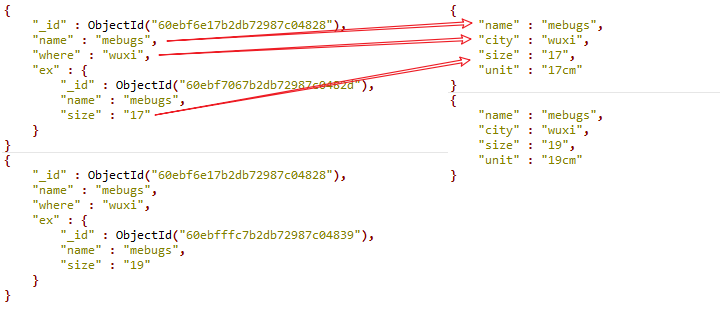
这样的输出结果是不是立马清爽了很多?程序应用处理起来更加方便。
增强语法实例
MongoDB 3.6 版本的增强语法,仅仅看描述会很困惑,我们直接编写一个实例,会更加容易理解。
增强语法最大的特点是提供了管道能力,可以实现更为复杂的条件过滤和自定义文档的返回。
db.getCollection("USER").aggregate([
{
$lookup: {
from: "USER_EX",
let: { queryName: "$name", queryCity: "$where" }, // 定义两个变量,分别取主表 name 和 where 字段
pipeline: [
{
$match: {
$expr: { // 读取管道变量
$and: [
{
$eq: ["$name", "$$queryName"], // 附表的 name 字段等于 queryName 变量
$eq: ["$where", "$$queryCity"] // 相当于匹配附表 name 和 where 与主表相同的内容
}
]
}
}
},
{
$project: { // 定义 Join 进来的输出内容
_id: 0,
size: { $concat: ["$size", "cm"] }
}
}
],
as: "ex"
}
}
])
查询结果:
{
"_id" : ObjectId("60ebf6e17b2db72987c04828"),
"name" : "mebugs",
"where" : "wuxi",
"ex" : [
{
"size" : "17cm"
},
{
"size" : "19cm"
}
]
}


当前还没有观点发布,欢迎您留下足迹!




同类其他
数据库
Linux下Oracle数据库配置日志目录及统一迁移
很多运维人员习惯采用默认安装的方式安装Oracle数据库,而Oracle日志默认放置在/opt目录下,绝大多数Linux环境的大磁盘往往挂载在/home,因此经常会出现磁盘空间不足的情况,采用本文配置可指定并迁移日志

Oracle数据库基础实用维护命令集
Linux系统下的Oracle数据库实用常用的维护命令整理,本文内容偏向运维,主要包含:基础启动重启、表空间维护、数据库角色与用户维护、字符集配置等,并给出各类场景的实例语句

ORA-00257: archiver error. Connect internal only, until freed.
登录Oracle报错 ORA-00257: archiver error. Connect internal only, until freed. 由于归档日志(archive log)已满引起的。

Oracle存储过程Procedure基础语法
存储过程是个好东西,WEB工程在架构阶段会设计很多存储过程,后续在架构中开发需求的时候,反而会直接写SQL完成各项诉求。所以说,这玩意儿略微有那么一点点伪高端。

Oracle数据库MERGE INTO语句条件入库
Oracle 9i版本引入MERGE INTO语句,其主要用于实现条件入库能力,用于解决对于已有数据更新升级的情况,即可实现不存在数据则插入,存在数据则更新的分支判断形式的更新能力

SQL语句中DELETE、TRUNCATE和DROP的区别
当我们需要清理或删除某张表或数据的时候,通常会有采取DELETE、TRUNCATE、DROP的任意一种形式的SQL语句,他们之间作用的对象不同所产生的效果也各不相同,包括执行结果和效率










