
解决高并发访问的最为直接的方式是应用缓存,除了常见的本地缓存之外,我们还可以引入分布式缓存(如Redis),分布式缓存在系统架构中有什么优势和应用价值是什么呢?
缓存的意义
缓存的意义主要用于解决数据库访问压力,提升数据返回速度。
见下图;
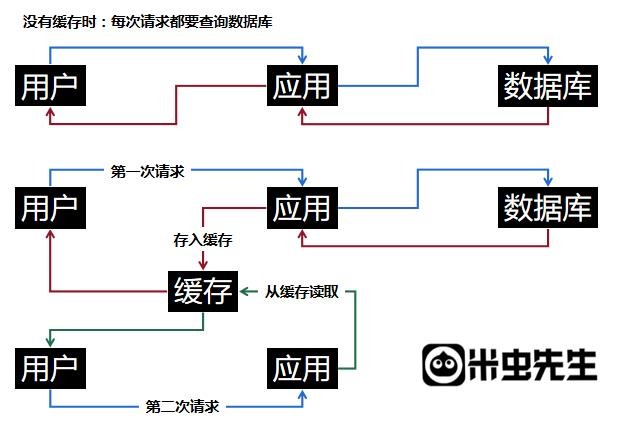
从上图我们可以清晰的明白缓存的意义。
那么缓存可以解决什么问题呢?
- 数据库访问瓶颈(减少了数据库访问的次数)
- 应用访问瓶颈(减少了单次访问的时间)
本地缓存
所谓本地缓存即应用自身直接开辟使用的内存空间。
一般来说,为了解决高并发访问时,第一步基本会采用本地缓存方案。
本地缓存的优点:
- 访问速度快:
本地缓存不需要跨网络传输,具有超高的性能
本地缓存的缺点:
- 内存竞争;
本地缓存占用了应用进程的内存空间,会与应用的其他内存进行竞争 - 重启或异常丢失:
本地缓存的数据是存储在应用进程的内存空间的,当应用进程重启或异常,本地缓存的数据会丢失
当然可以通过持久化的方式解决,但才用了持久化实际上就弱化了性能 - 集群组网缓存同步:
本地缓存只支持当前节点的应用进程访问,如果在集群组网下的多节点之间可能出现缓存不一致
此外,多节点间的缓存同步逻辑复杂且带来很多不可控的因素(如同步失败、节点重启等等)
就如下图所示:
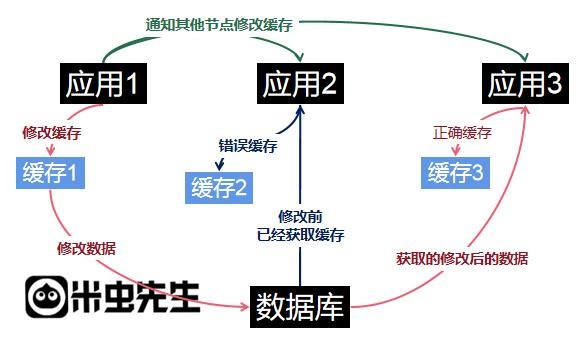
当应用节点越来越多的时候,我们在修改数据后要不断去考虑如何解决缓存同步的问题。
而在解决缓存同步的过程中会暴露越来越多的问题:
- 节点越来越多,缓存同步通知开销越来越大(额外的性能开销)
- 为了保证缓存同步,需要维护一个节点列表,并不断同步各个节点的存活状态(额外的业务逻辑)
- 某些节点异常时可能导致通知进程的异常(可能导致通知丢失)
- 某些节点尚未收到同步通知之前收到新的访问请求(错误缓存被读取)
分布式缓存
分布式缓存也是缓存,唯一的区别就在于,在整个架构体系中是完全独立的一个进程。
分布式缓存的优点:
- 无内存竞争/不受重启影响:
独立部署的进程,独立的内存空间,不会受到应用进程重启的影响(甚至可以将分布式缓存单独部署在其他的网络节点)
应用进程重启时,分布式缓存的数据依然存在 - 存储容量的不受限:
分布式缓存一般可以单独部署在一个新的网络节点,在内存方法几乎不受其他应用影响
同时分布式缓存也可以通过集群组网的方式进行容量拓展 - 数据一致性:
分布式缓存一般给整个集群的其他网络节点进行统一缓存数据存取操作
不存在本地缓存中的数据更新问题,保证了不同节点的应用进程的数据一致性问题 - 读写分离:
分布式缓存本身技术架构中多数支持读写分离,能够提供较高的访问性能
分布式缓存的缺点:
- 额外开销:
无论分布式缓存与应用是否安装在同一个网络节点均会增加少量的应用开销
此外,如果进行多节点部署或跨网络部署会增加额外的网络开销
就如下图所示:
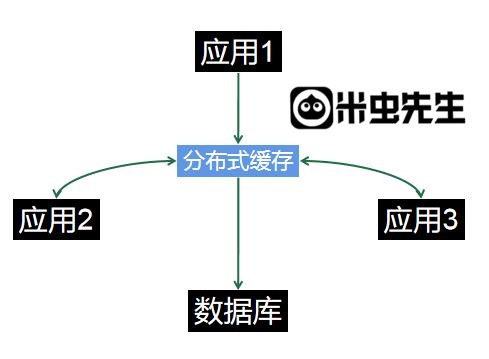
常见两种分布式缓存
MemCached
MemCached 相对于本地缓存的主要差别是以独立进程方式存在,数据集中存储,数据不随应用程序的重启而丢失。
而 key-value 键值对的 value 也是一个简单的对象类型,即 value 可以是任意格式的数据,如简单的数字、字符串、对象等,也可以是文件、图像、视频等复杂格式的数据,但是不支持数据结构的特性。
所以 MemCached 进程相当于是在内存维护了一个非常大的哈希表来存储数据,对应的数据操作复杂度都是 O(1),即常量级别。
这也是 MemCached 高性能的一个实现方式,键值对存取速度都非常快。
Redis
Redis 更一步丰富了 key-value 键值对的 value 的数据结构类型,即可以在 Redis 中完成 value 的相关数据操作,如 Set 集合、有序集合 ZSet 等,这样就不需要在应用程序额外进行这些操作,实现了开箱即用。
Redis 是单线程的,不存在并发数据读写的线程安全问题,以及更重要的是保证的数据读写操作的顺序性。
Redis 支持主从同步(读写分离)、集群分片拓展、数据持久化等特性,这也是 MemCached 不支持的。
所以在某些高并发场景下(如日志)Redis 完全可以作为数据库来使用,提高高并发场景中的访问性能。
- 缓存的意义
- 本地缓存
- 分布式缓存
- 常见两种分布式缓存
- MemCached
- Redis
相关阅读









发表评论

温馨提示:系统将通过浏览器临时记忆您曾经填写的个人信息且支持修改,评论提交后仅自己可见,内容需要经过审核后方可全面展示。
选择头像











